LruCache工作原理
LruCache是基于least recently used算法实现的使用strong reference引用有限数量值的缓存机制,内部使用LinkedHashMap存储键值对,它内部维护一个双向链表,当插入某个键值对时,将其链接到双向链表的尾端tail端,当访问某个键值对时,将此键值对移动至尾端tail端,tail指向的键值对最年轻(youngest),head指向的键值对最老(eldest),当数据超过maxSize时,LruCache会移除head端的键值对。
构造函数
LruCache内部使用LinkedHashMap存储数据,同时设置最大缓存大小maxSize1
2
3
4
5
6
7public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}
put方法
LruCache不允许null值,key或value都不允许,同时put操作是线程安全的1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
putCount++;
size += safeSizeOf(key, value);
previous = map.put(key, value);
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
entryRemoved(false, key, previous, value);
}
trimToSize(maxSize);
return previous;
}
private int safeSizeOf(K key, V value) {
int result = sizeOf(key, value);
if (result < 0) {
throw new IllegalStateException("Negative size: " + key + "=" + value);
}
return result;
}
protected int sizeOf(K key, V value) {
return 1;
}
默认一个键值对算作1个size大小,如果一个键值对要动态计算大小可以复写sizeof方法,例如1
2
3
4
5
6int cacheSize = 4 * 1024 * 1024; // 4MiB
LruCache<String, Bitmap> bitmapCache = new LruCache<String, Bitmap>(cacheSize) {
protected int sizeOf(String key, Bitmap value) {
return value.getByteCount();
}
}
当替换原value后需要做特定回收操作可以复写entryRemoved方法,最后还要判断是否超过缓存容量maxSize,若超过maxSize则移除最老的键值对1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
if (size <= maxSize) {
break;
}
Map.Entry<K, V> toEvict = map.eldest();
if (toEvict == null) {
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}
再看一下LinkedHashMap中eldest方法1
2
3public Map.Entry<K, V> eldest() {
return head;
}
head指向的entry视为最老的键值对,那LinkedHashMap又是如何维护它内部的双向链表的呢? LruCache调用的LinkedHashMap构造函数是:1
2
3
4public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
super是HashMap,所以创建了一个initialCapacity为0,loadFactor为0.75的HashMap,并且accessOrder为true,当执行get操作时会调整LinkedHashMap中双链表结构,即将访问的entry移至tail端,先看一下LinkedHashMap的put方法,发现它并没有复写put方法,但它复写了newNode方法,对HashMap.Node进行了封装,加入了用于构建双链表的before和after指针1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22static class LinkedHashMapEntry<K,V> extends HashMap.Node<K,V> {
LinkedHashMapEntry<K,V> before, after;
LinkedHashMapEntry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMapEntry<K,V> p =
new LinkedHashMapEntry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMapEntry<K,V> p) {
LinkedHashMapEntry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
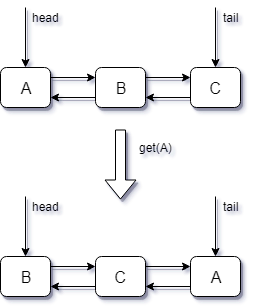
创建node的同时构建双链表,将head指向最先加入的entry,tail指向最新加入的entry,再看LinkedHashMap的get操作1
2
3
4
5
6
7
8public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
可以看到当accessOrder == true时会执行afterNodeAccess方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMapEntry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMapEntry<K,V> p =
(LinkedHashMapEntry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
这段代码的意思是将e节点移至tail端,其他节点的顺序保持不变,原节点的前后节点相连接,所以tail指向的entry是最年轻的,head指向的节点最老
分析完成。